【SEO基礎知識】クローラビリティとは?初心者向けに解説!
マーケティング担当者であれば、一度は「SEO対策」という言葉を耳にしたことがあると思います。中には、SEO対策が重要だということがわかっているけどまずなにからすればいいのかわからない...と手をつけられていない方も多いのではないのでしょうか。
SEO対策を始めるためにはまず、Googleなどの検索エンジンにあなたのWebサイトの情報が登録されなければ意味がありません。このとき、Webサイトの情報を収集するロボットのことを「クローラー」といいます。
今回はクローラーについて、そしてどうすればSEO対策につながるのかをご紹介します。

クローラー?インデックス?よく聞くワードを解説!
はじめに、SEO対策について調べるときに必ず出てくるといわれる用語をまとめて解説します。
クローラーとは
クローラーとは、Googleなどの検索エンジンがWeb上の情報(Webサイト・画像・PDF・HTML文書など)を収集するためのプログラムのことです。。Webサイト上を「這う(クロールする)」ことから「クローラー」と呼ばれています。
クローラーは「インターネット上でWebサイトのページ情報を収集する」プログラムとして動いています。この作業をクローリングと言います。つまり、Webサイトが検索エンジンの検索結果に表示されるには、クローラーの巡回で自社のサイトがしっかりと認識されることが必要になります。
インデックスとは
インターネットにつながっているWebサイト・画像・PDF・HTML文書などの情報を収集し、検索データベースに保管することを「インデックス化」といいます。索引や見出しといった意味を持つ言葉で、格納されたデータをより早く検索したり、抽出できるように作られる索引データのことです。
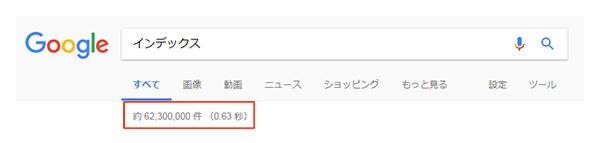
Googleで検索したときに上に出てくる「約10,000,000件」といった数字を見たことがありませんか?この件数をインデックス件数と言い、検索キーワードに関連すると検索エンジンが判断したインデックス済みページ数になります。
では、インデックスが多い、すなわちページ数が多い方ががSEO対策には有利なのでしょうか?答えはYesでもあり、Noでもあります。検索されたキーワードに関連するページが多ければYesという答えになりますし、全く関係のない適当なページが多ければ答えはNoになります。むやみにページ数を増やせばいいってわけでもないのです。
クローラーは各検索エンジンごとに存在する?
検索エンジンごとにクローラーは存在しますが、その中でも最も有名なのはGoogle botではないでしょうか。
Google botはGoogleのWeb上におけるクローラーで、さまざまな種類があります。Googleの画像検索にはGoolebot-Image,モバイル検索にはGooglebot-Mobileといった種類のクローラーが存在します。
YahooはGoogleの検索順位を採用しているため、Googleのクローラーを意識していればYahooのSEOも対策できるといえます。日本の検索エンジンのシェアはGoogleとYahooで約9割を占めているので、実質Googlebotを気にしていれば良いと言っても過言ではないでしょうか。ですので、ここから先はGoogle botのクローラー対策についてご紹介します。
クローラビリティってなに?
「クローラビリティを上げる」という言葉を耳にしたことがある人もいるのではないでしょうか。クローラビリティとは簡単に言えば、クローラーがクロールしやすいようにする、つまりクローラーがサイト内を巡回しやすいようにすることです。クローラビリティを向上させればそれだけクローラーがサイト内をうまく巡回してくれるということになるので、SEO対策にも繋がります。
クローラーはインターネット上に繋がっていれば、できるだけWebサイト上を巡回し、情報収集をしようとします。しかし、クローラーはすべてのWebサイトを漏れなく巡回することはできません。また、公開してすぐにWebサイトを発見し、巡回してくれるとも限りません。こちらからクローラーが見付けやすくしてあげることで、いち早く 検索結果に表示されるようになります。
つまり、いかに効率よくクローラビリティをあげてWebサイト内を巡回させるかがSEOの順位をあげるかというポイントになります。
では、クローラビリティを上げるにはどうすればいいのでしょうか?
クローラビリティを向上させるには
1.クローラーがクロールできる状態にする
クローラーがWebサイト上を巡回するためには、クローラーにWebサイトを発見してもらわないと意味がありません。クローラーが見るWebサイトと、私たちユーザーが見るWebサイトは見方が全く異なるため、クローラーが読み取れるテキスト情報が不可欠というわけです。クローラーが読み取れる情報が不足、もしくは不適切な場合は検索結果に反映されないということもあります。
2. リンク階層
GoogleはURLの長短はランキングに関係ないと宣言しています。しかし、URLの階層は関係してきます。例えば、AとBのURLがあった場合、Aのほうが重要視されるそうです。
A https://www.innovation.co.jp/urumo/
B https://www.innovation.co.jp/urumo/exhibition_achievement/
重要視されるということは、URLが発見しやすいということです。つまり、階層が浅いほうが先に発見されやすいということになりますね。
3.Google Search Consoleでサイトマップが正しく送信されているか確認する
ここでいう「サイトマップ」とはGoogleなどの検索エンジンにホームページの存在を示すことができるXMLファイルのことを指します。このsitemap.xmlを正しく作成し適したディレクトリに設置していればGoogleクローラーはサイトマップを読み込んでくれます。しかし、記述に誤りがあったりすると読み込んでもらえなくなってしまうため、Googleが提供しているツール「Google Search Console」で正しくsitemap.xmlが読み込まれているかを確認しましょう。
4.Google Search ConsoleのFetch as Googleを活用する
Fetch as Googleは、Googleにクロールを促す機能があります。サイト更新したり、新しいページを追加したなど、すぐにGoogleにページを読み込んでもらいたい場合は活用できます。
5. リンクのないページを排除する
先述しましたが、クローラーはURLを見つけてリンクに飛びます。そのため、存在しないページに遷移するリンクがないかを確認し、削除していきましょう。
6. パンくずリストの設定
「パンくずリスト」とは、ユーザーが閲覧しているページがホームページ全体のどの位置なのか、階層なのかがわかる、いわば案内図のようなものです。これを設定することによって、クローラーに発見されやすくなりますが、施策を試したからといって、必ずしもクローラーが巡回しにくるわけではありません。なぜなら、Google次第であるからです。
以上のような対策をしてクローラビリティが向上しても、クローラーがWebサイトにきていることがわからなければ意味がないですよね。ではどうすればわかるのでしょうか?
クローラーがWebサイトにきているか確認しよう!
主な方法は2つあります。
1. 「site:検索」を使用
「site: www.innovation.co.jp/urumo/」のように、「site:クローラーが来ているか調べたいURL」でGoogle検索をかけることによって、そのページにクローラーがきているのかがわかります。もし、そのページが表示されない場合は、Fetch as Googleでクロール申請をかけたり、インデックスを防ぐnoindexの記述がないかなど確認しましょう。
2. Google Search Consoleを使い、「クロールの統計情報」を閲覧。
Google Search Console内の「クロール」→「クロールの統計情報」にて、クローラーがどれくらいあなたのWebサイト情報を読み込んでいるのかを見ることができます。なにもしていないのに極端に増えた・減ったなどした場合は原因を探ってみましょう。
これらの方法であなたのWebサイトがどれくらいクロールされたのかが数値で確認できます。もしこの数値が低いようでしたら、施策をもう一度見直すべきです。
さいごに
今回はクローラーとはなにかということをお話しました。きちんとした対策をしないとせっかく作ったWebサイトがクローラーに認識されず、検索順位が上がりません。ぜひ一度あなたのWebサイトのクローラビリティを見直してみてはいかがでしょうか。
これを読んでもっとUrumo!
この記事を読んだあなたに、さらにステップアップできる記事をご紹介します。




